Failover چیست؟ و چگونه کار میکند؟
Failover توانایی تغییر خودکار و یکپارچه به یک سیستم پشتیبان قابل اعتماد هنگام بروز مشکل یا اختلال است. هنگامی که یک مؤلفه یا سیستم اولیه خراب میشود، یک سیستم آماده به کار یا در حالت افزونگی باید Failover را محقق کرده و تأثیر منفی روی کاربران را کاهش داده یا حذف کند.
برای دستیابی به افزونگی در صورت خرابی یا خاتمه کار غیرعادی یک سیستم که پیش از واقعه در حال فعالیت بوده، یک پایگاه داده آماده به کار، سیستم، سرور، یا سایر اجزای سختافزاری یا شبکه باید همیشه آماده باشد تا به طور خودکار وارد عمل شود. به عبارت دیگر، تمام تکنیکهای پشتیبانگیری، از جمله سیستمهای سرور کامپیوتر آماده به کار، باید خودشان هم در برابر خرابی مصون باشند، زیرا Failover برای بازیابی فاجعه (DR) حیاتی است.
Failover چیست؟
سیستم اتوماسیون Failover در سرورها شرایطی شبیه به پایش ضربان قلب دارد. یعنی کابلهای ضربان قلب دو سرور یا چندین سرور را در یک شبکه با سرور اصلی همیشه فعال متصل میکنند. تا زمانی که ضربان قلب ادامه دارد، سرور ثانویه فقط استراحت میکند. با این حال، اگر سرور ثانویه هر گونه تغییری در ضربان قلب را به خاطر خرابی سرور اصلی شناسایی کند، وارد عمل شده و عملیات سرور اولیه را در اختیار میگیرد. همچنین به تکنسین یا مرکز داده پیام میدهد که سرور اصلی را دوباره آنلاین کنند. برخی از سیستمها که با نام «خودکار با پیکربندی تأیید دستی» شناخته میشوند، به جای تغییر خودکار، فقط به تکنسین یا مرکز داده هشدار میدهند و درخواست میکنند که تغییر در سرور به صورت دستی انجام شود.
در حالتی که به جای سرورهای فیزیکی مجزا از فرایند مجازی سازی استفاده شده باشد شرایط متفاوت خواهد بود. مجازی سازی یک محیط کامپیوتری را با استفاده از شبه ماشینی که نرمافزار میزبان را اجرا میکند یا یک ماشین مجازی (VM)، شبیه سازی میکند. به این ترتیب، فرآیند Failover میتواند مستقل از اجزای سختافزار فیزیکی سیستمهای سرور رایانه باشد.
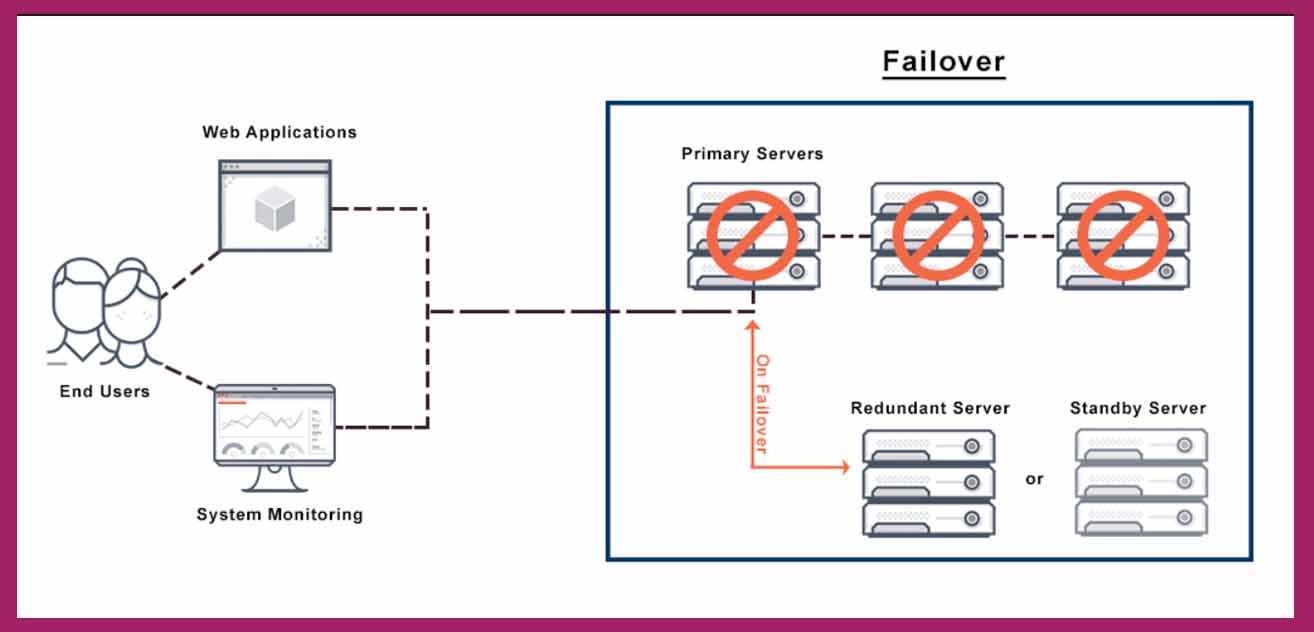
Failover چگونه کار میکند؟
فعال-فعال و فعال-غیرفعال یا فعال-آماده به کار رایجترین پیکربندیها برای دسترسی بالا (HA) هستند. هر کدام از تکنیکها به روشی متفاوت Failover را امکان پذیر میکند، اگرچه هر دو، قابلیت اطمینان را بهبود میبخشند. به طور معمول، حداقل دو گره که به طور فعال و به طور همزمان یک نوع سرویس را اجرا میکنند، یک خوشه فعال-فعال با دسترسی بالا را تشکیل میدهند. خوشه فعال-فعال بارهای کاری را در تمام گرهها به طور یکنواخت توزیع میکند و از بارگذاری بیش از حد هر گره جلوگیری میکند. در این حالت چون گرههای بیشتری در دسترس باقی میمانند، توان عملیاتی و زمان پاسخ بهبود مییابد. برای اطمینان از عملکرد یکپارچه خوشه HA و دستیابی به افزونگی، پیکربندی و تنظیمات جداگانه گرهها باید یکسان باشد.
در مقابل، در یک خوشه فعال- غیرفعال، اگرچه باید حداقل دو گره وجود داشته باشد، اما همه آنها فعال نیستند. در یک سیستم دو گره با اولین گره فعال، گره دوم غیرفعال یا در حالت آماده به کار به عنوان سرور Failover باقی میماند. در این حالت در صورتی که فعالیت سرور اصلی متوقف شود، سرور دوم که پیش از این در حالت غیر فعال یا آماده به کار قرار داشته وارد عمل میشود. با این حال، اگر مشکلی وجود نداشته باشد، مشتریان فقط به سرور فعال متصل میشوند.
مانند آن چه در خوشه فعال-فعال دیدیم، هر دو سرور در خوشه فعال-استندبای باید با تنظیمات یکسان پیکربندی شوند. به این ترتیب، حتی اگر روتر یا سرور Failover وارد عمل شود، مشتریان متوجه تغییری در سرویس نخواهند شد. واضح است که در یک خوشه فعال-آماده به کار اگرچه گره آماده به کار همیشه روشن است، اما میزان استفاده واقعی نزدیک به صفر است.
در یک خوشه فعال-فعال، میزان استفاده از هر دو گره ۵۰-۵۰ است. اگرچه هر گره به تنهایی میتواند کل بار را اداره کند. با این حال، این وضعیت به این معنی است که اگر یک گره پیکربندی فعال-فعال بیش از نیمی از بار را به طور مداوم مدیریت کند، خرابی گره میتواند باعث کاهش عملکرد شود.
وقفه خدمات در هنگام خرابی با پیکربندی فعال-فعال HA تقریبا صفر است، زیرا هر دو مسیر فعال هستند. با یک پیکربندی فعال-غیرفعال، زمان وقفه بالقوه ممکن است طولانیتر باشد، زیرا سیستم باید از یک گره به گره دیگر سوئیچ کند، که به زمان نیاز دارد.
مقاله پیشنهادی“معرفی نوآوریهای جدید چند ابری (Multi-Cloud) ذخیرهسازی و حفاظت از دادهها”
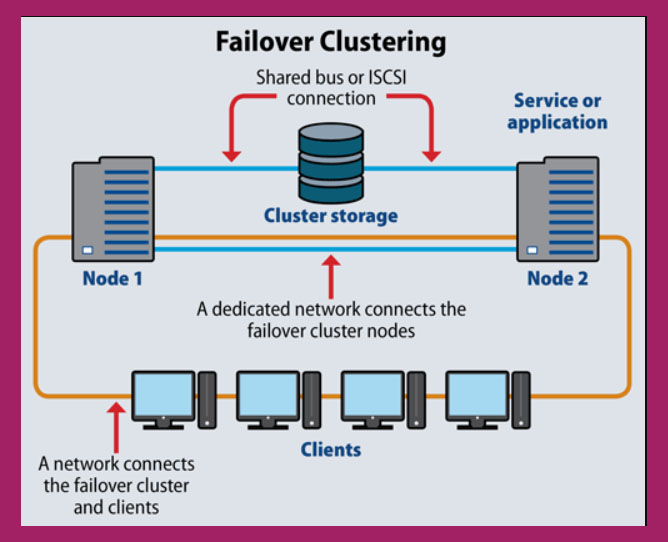
خوشه Failover چیست؟
یک خوشه Failover مجموعهای از سرورهای کامپیوتری است که تحمل خطا (FT)، در دسترس بودن پیوسته (CA) یا دسترسی بالا (HA) را با هم ارائه میدهند. پیکربندیهای شبکه خوشهای Failover ممکن است از ماشینهای مجازی (VM)، سختافزار فیزیکی صرف یا هر دو استفاده کنند. اگر یکی از سرورهای یک خوشه Failover از کار بیفتد، فرآیند Failover آغاز میشود. هدایت فوری بار کاری گره از کار افتاده به گره دیگری در خوشه، از وقفه ارائه خدمات در کل مجموعه جلوگیری میکند.
ارائه HA یا CA برای برنامهها و سرویسها، هدف اصلی یک خوشه Failover است. این خوشهها همچنین به عنوان خوشههای تحمل خطا (FT) هم شناخته میشوند، خوشههای CA زمانی که سیستمهای اصلی یا اولیه از کار میافتند، وقفه را از بین میبرند و به کاربران نهایی امکان میدهند بدون وقفه به استفاده از برنامهها و خدمات ادامه دهند.
در مقابل، با وجود یک وقفه کوتاه بالقوه در سرویس، خوشههای HA حداقل زمان خرابی، بازیابی خودکار و بدون از دست دادن داده را ارائه میدهند. فرآیند بازیابی در خوشههای HA را میتوان با استفاده از ابزارهای مدیریت خوشه Failover، که به عنوان بخشی از اکثر راهکارهای خوشه Failover گنجانده شده است، پیکربندی کرد.
در یک مفهوم گستردهتر، یک خوشه دو یا چند گره یا سرور است که معمولا هم به صورت فیزیکی با کابل و هم از طریق نرمافزار به هم متصل میشوند. فناوریهای خوشهبندی اضافی مانند پردازش موازی یا همزمان، متعادلسازی بار و راهحلهای ذخیرهسازی ابری هم در برخی از پیادهسازیهای Failover گنجانده شدهاند.
Failover اینترنتی اساسا یک اتصال اینترنتی اضافی یا ثانویه است که در صورت خرابی به عنوان یک پیوند Failover استفاده میشود. این را میتوان به عنوان یکی دیگر از قابلیتهای Failover در سرورها در نظر گرفت.
Failover سرور برنامه چیست؟
سرورهای برنامه صرفا سرورهایی هستند که برنامههای کاربردی را اجرا میکنند. این بدان معنی است که Failover سرور برنامه یک استراتژی Failover برای محافظت از این نوع سرورها است. به عنوان حداقل پیشنیاز، این سرورهای برنامه باید دارای نامهای دامنه منحصر به فرد باشند و در حالت ایدهآل باید روی سرورهای مختلف اجرا شوند. بهترین شیوههای خوشه Failover معمولا شامل متعادل کردن بار سرور برنامه است.
آزمون Failover چیست؟
آزمون Failover ظرفیت سیستم را در هنگام خرابی سرور در تخصیص منابع کافی برای بازیابی بررسی میکند. به عبارت دیگر، آزمون Failover قابلیت Failover در سرورها را ارزیابی میکند. این آزمایش تعیین میکند که آیا سیستم در صورت هرگونه خاتمه غیرعادی یا خرابی، در مدیریت منابع اضافی لازم و انتقال عملیات به سیستمهای پشتیبان یه درستی عمل میکند یا خیر. به عنوان مثال، تست Failover و بازیابی، توانایی سیستم را برای مدیریت و تامین انرژی یک CPU اضافی یا چندین سرور پس از رسیدن به آستانهای برای عملکرد مشخص میکند. آستانهای که اغلب در هنگام خرابیهای بحرانی نقض میشود. این امر رابطه مهم بین تست Failover، انعطافپذیری و امنیت را برجسته میکند.
Failover and Failback چیست؟
در فناوریهای پردازشی و موضوعات مرتبط با آن، مانند شبکه، Failover فرآیند جابجایی عملیات به یک وسیله بازیابی پشتیبان است. سایت پشتیبان در Failover عموما یک شبکه رایانهای آماده به کار یا افزونه، جزء سختافزاری، سیستم یا سرور است که اغلب در یک مکان بازیابی فاجعه ثانویه (DR) قرار دارد. به طور معمول، Failover شامل استفاده از نوعی از یک ابزار یا سرویس Failover برای توقف موقت و راه اندازی مجدد عملیات از یک مکان راه دور است.
عملیات Failback شامل بازگشت تولید به محل اصلی خود پس از یک دوره تعمیر و نگهداری برنامه ریزی شده یا یک حادثه است. این بازگشت از حالت آماده به کار به حالت کاملا کاربردی است. به طور معمول، طراحان سیستمها قابلیت Failover را در سیستمها، سرورها یا شبکههایی ارائه میکنند که CA، HA یا سطح بالایی از قابلیت اطمینان را میخواهند. به لطف استفاده از نرمافزار مجازیسازی، شیوههای Failover با اختلال کم یا بدون اختلال در سرویس، وابستگی کمتری به سختافزار دارند.
جمع بندی
اکنون بیش از هر زمان دیگری، تهدیدات ناشی از مهاجمان سایبری و دادههای مربوط به کارکنان دورکار در حال افزایش است. دادهها سوخت مورد نیاز برای تحرک شرکت شما هستند، بنابراین ضروری است که با یک استراتژی قوی DR از آن محافظت کنید. هدف اصلی Failover متوقف کردن یا حداقل کاهش شکست کامل سیستم است. اگر زیرساخت شبکه به درستی پیکربندی شده باشد، آنگاه Failover و Failback یک حفاظت یکپارچه و کامل در برابر بیشتر یا نه تمام اختلالات سرویس ارائه خواهند کرد.